Beschreibung
Dieses Teilprojekt hat bisher neue "Multicore-Architekturen", die eine hohe Performance Computing (HPC)-Fähigkeit bieten, untersucht.
Darüber hinaus, wurden die Programmierung / Software-Techniken erfolgreich entwickelt, die notwendig sind um diese Prozessoren zu programmieren. Die größte Herausforderung bei der Nutzung dieser Prozessoren ist es den hohen Grad an Parallelität durch eine große Anzahl von Kernen auszunutzen.
Beispiele für solche bisherigen Architekturen sind Tesla C1060 und C2050 GPUs (entwickelt von NVIDIA) mit bis zu 512 Cores pro Knoten, Nehalem-Cluster im HLRS, und die neue Cray XE6 mit seiner neuen Gemini Zusammenschaltung, welche bis zu 10 Mio. MPI Nachrichten pro Sekunde bearbeiten kann. Diese Systeme wurden ausgewählt, weil ihre Leistung eine gute Wirksamkeit für eine große Anzahl von Anwendungsprogrammen aufweisen. Darüber hinaus wird die neue Maschine eine Spitzenleistung über ein Petaflop erreichen (Abbildung 1).
Als einer der ersten Hersteller von Grafikchips hat NVIDIA 2006 mit der Entwicklung von CUDA (Compute Unified Device Architecture) eine Programmierschnittstelle der GPU für allgemeine Anwendungen zur Verfügung gestellt (General Purpose GPU, kurz GPGPU). Danach haben sich viele Programmiermodelle entwickelt worden um die Parallelisierung der neue viele Kerne Systeme und Beschleunigern auszunutzen, wie CAPS-HMPP und OpenACC.
Die neueste Generation NVIDIA Tesla GPU-Beschleuniger liefert eine Spitzenleistung, die für Berechnungen einfacher Genauigkeit bis zu 1.03 TFLOPS erreicht und zugleich weniger Energie pro Flop verbraucht. Somit ist der Wirkungsgrad von Operationen / Watt besser als jeder andere superskalare Prozessor.
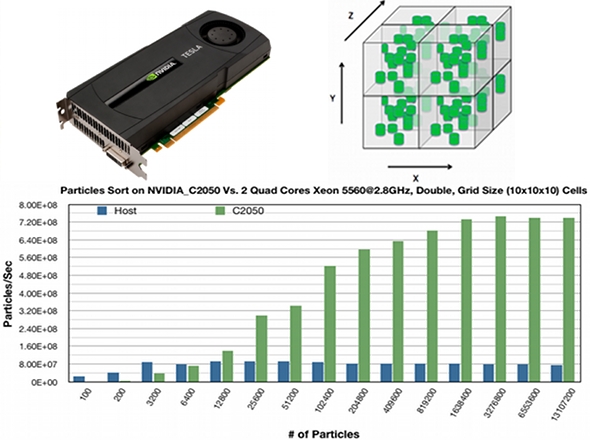
PASIMODO (PartikelSImulation und MOlekularDynamik in einer Objektorientierten Weise), entwickelt am Institut für Technische und numerische Mechanik (ITM) der Universität Stuttgart, wurde ausgewählt, um in der ersten Phase auf NVIDIA-GPUs optimiert und portiert zu werden. Wie der Name sagt, wird diese Simulationsanwendung vor allem für die dynamische Simulation von granularen Medien, wie Sand und Kies auch in Mischungsvorgängen verwendet.
Das Teilprojekt D.2 arbeitet hierfür hauptsächlich mit A.5 zusammen, PASIMODO wird mit verschiedenen Software-Analyse und Profiling-Tools (wie Valgrind, gprof, Vtune .... etc) analysiert, der zeitaufwändigste Teil in dem PASIMODO Code wird extrahiert, parallelisiert und auf die GPGPU portiert. Als Ergebnis wird die Parallelisierung in zwei Ebenen sein: Grob-und feingranuläre Parallelität.
Die grobgranuläre Parallelität wird verwendet, damit zwei oder mehr verschiedene unabhängige Codes auf zwei oder mehr GPGPUs ausgeführt werden. Auf der anderen Seite wird die feingranuläre Parallelität verwendet, um die SIMD- und SIMT-Fähigkeiten zu nutzen. Diese Arbeit stellt zwei schwierige Anforderungen. Zum einen müssen zur vollen Auslastung der Hardware-Ressourcen, alle Anforderungen der Hardware, wie Datentransfer, -zugriff, sowie -Ausrichtung, und die Speicherhierarchie erfüllt werden (Hardware-Nahe Programmierung). Andererseits sollte der Code möglichst intakt gehalten werden.
|
|