Description
This subproject has so far investigated new "multicore architectures" that provide a high performance computing (HPC) capability. In addition, the programming/software techniques which are necessary to program these processors have been successfully developed. The main challenge using those processors is to exploit the high degree of parallelism provided by means of utilizing large number of cores.
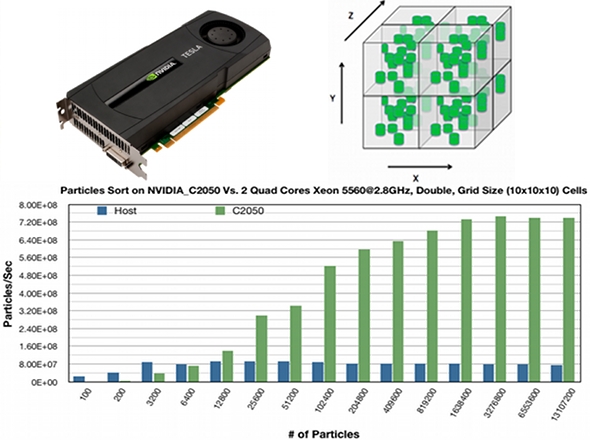
Examples of those recent architectures are Tesla C1060 and C2050 GPUs (developed by NVIDIA) with up to 512 cores per node, Nehalem Cluster at HLRS, and the New Cray XE6 with more that 113,000 cores and a new Gemini interconnection, which may handle up to tens of millions MPI messages per second. These systems have been selected because their performance shows good efficiency for a large number of codes. Furthermore, the new machine will achieve a peak performance over a one PetaFlop. Using GPUs in the general purpose parallel computing (GPGPU) offers heterogeneous programming models, which were first exploited by developing CUDA (Computed Unified Device Archeticture) in 2006 by NVIDIA and then many programming models have been developed to exploit the parallelization of the new many-cores systems and accelerator like CAPS-HMPP and OpenACC. The newest generation NVIDIA Tesla GPU accelerator delivers a peak performance that reaches up to 1.03 TFLOPS for a single precision and consumes less power per Flop at the same time. This means that the operation/watt efficiency is better than any other superscalar machines (Figure 1).
PASIMODO (PArticle SImulation and MOlecular Dynamics in an Object oriented fashion), developed by the Institute of Engineering and Computational Mechanics (ITM) at the University of Stuttgart, has been selected to be optimized and ported to NVIDIA GPUs at the first phase. From its name, this simulation is used mainly for the dynamic simulation of granular objects like sand and gravels and others.
The subproject D.2 done collaboration with A.5, PASIMODO has been analyzed using different software analysis and profiling tools (such as Valgrind, GProf, Vtune.... etc). The most time consuming part in the PASIMODO code will be extracted, parallelised and ported to the GPGPU. As a result, the parallelisation will be in two levels: coarse and fine grained parallelism.
The coarse grained parallelism will be done to allow two or more different independent codes to be running on two or more GPGPUs. On the other hand, the fine grained parallelism is used to exploit the SIMD and SIMT capabilities.
The challenge of this work is coming for two different aspects. To get a full utilization of the hardware resources, all the restrictions on how to access the data, data alignment, and it's memory hierarchy must be met (Hardware-dependent Programming). Of course, at the same time the code must be kept intact as much as possible.
|
|