Ergebnisse
Viele Messungen wurden auf GPUs durchgeführt, um die Effizienz der Portierung von MD-Simulationen auf GPUs zu ermitteln:
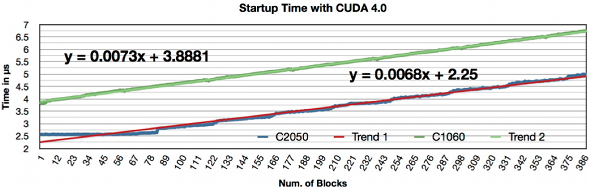
- CUDA-Kernel Overhead Zeit
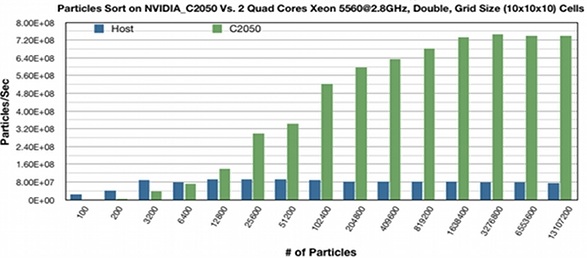
- Die Partikel-Sortierung auf einer NVIDIA C2050 GPU wurde mit einer parallelen CPU-Version verglichen. Eine Beschleunigung um den Faktor 9x wurde erzielt.
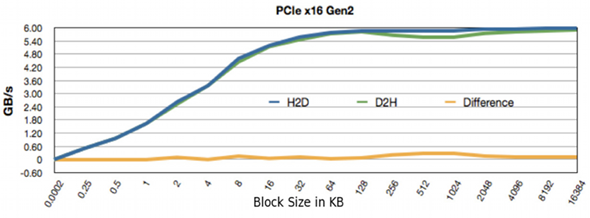
- Die Datenübertragungsrate über PCIe x16 zwischen Devicespeicher (GPU) zu page-locked Hostspeicher (CPU) ist ca. 6 GB/s
- Eine Billard-Simulation wurde für die "Kids Week" Veranstaltung entwickelt. In seiner ersten Phase führt es 2400 MFLOPS auf einem Single-Core Xeon 5560
 2.8GHz für ein System von 200 Teilchen und für 1000 Iterationen. Abbildung 4 zeigt den Billardtisch mit 200 Kugeln, die mit Povray generiert wurde.
2.8GHz für ein System von 200 Teilchen und für 1000 Iterationen. Abbildung 4 zeigt den Billardtisch mit 200 Kugeln, die mit Povray generiert wurde.
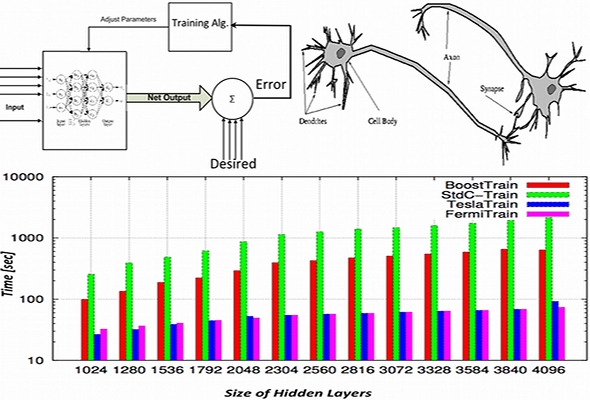
- Ein weiteres Beispiel für eine erfolgreiche Portierung von Simulationsprogrammen zur GPU ist die Portierung eines industriellen neuronalen Netzes. Diese Portierung führt zu einer Beschleunigung um den Faktor 12 im Vergleich zur ursprünglichen Implementierung.
|
|
|
|
|
|
|
|

|
|