Results
Many measurements have been done on GPUs in the first phase to find out the efficiency of porting MD simulations to GPUs:
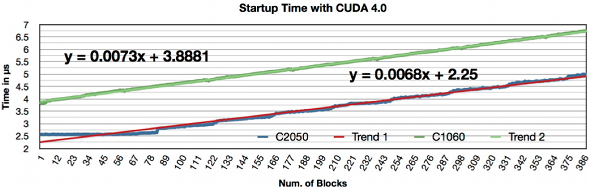
- CUDA Kernel startup time overhead.
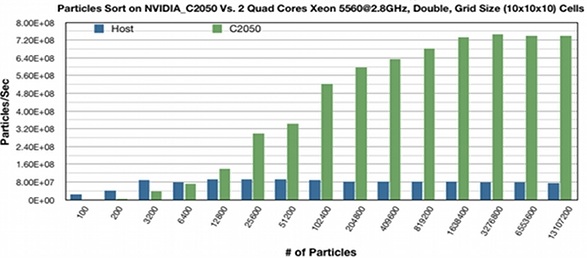
- Bucket sorts on GPU C2050 has been compared with a parallel CPU version. 9x speedup has been delivered
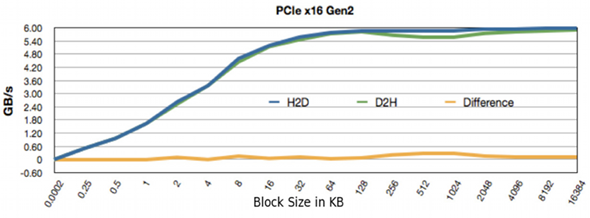
- Data transfer rate over PCIe x16 between device memory (GPU) to page-locked host memory (CPU) is about 6 GB/s.
- Moreover for Kids Week event a billiard simulation has been developed and in its fist phase it performs 2400 MFLOPS on a single core Xeon 5560
 2.8GHz for a system of 200 particles and for 1000 iterations. Figure 4 depicts the billed table with 200 balls generated using POVRAY.
2.8GHz for a system of 200 particles and for 1000 iterations. Figure 4 depicts the billed table with 200 balls generated using POVRAY.
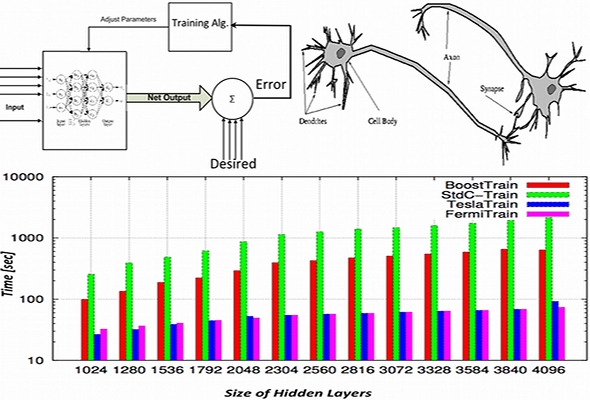
- Another example in a successful porting of simulation codes to GPU is porting an industrial neural network. This porting results in a speedup of 12x comparing to the original implementation.
|
|
|
|
|
|
|
|

|
|